OpenAI Gym
Today I made my first experiences with the OpenAI gym, more specifically with the CartPole environment. Gym is basically a Python library that includes several machine learning challenges, in which an autonomous agent should be learned to fulfill different tasks, e.g. to master a simple game itself. One of the simplest and most popular challenges is CartPole. It’s basically a 2D game in which the agent has to control, i.e. move left or right, a cart to balance a pole standing perpendicularly on the cart. This is a classical reinforcement learning problem, e.g. a scenario, in which the agents starts by trying random actions as a consequence to which it gets rewarded (or not). Based on the rewards, it continuously “learns”, which action is good in which specific situation. Doing so, it learns how to master the game without ever being told how the game even works. The main advantage of this type of learning is, that it’s completely generic and not bound to a specific problem. E.g. to learn a chess agent, you don’t need to “tell” it the rules of chess, but just let it do trial & error, whereas “error” means giving it a negative (or small positive) reward.
CartPole-v0
In machine learning terms, CartPole is basically a binary classification problem. There are four features as inputs, which include the cart position, its velocity, the pole’s angle to the cart and its derivative (i.e. how fast the pole is “falling”). The output is binary, i.e. either 0 or 1, corresponding to “left” or “right”. One challenge is the fact that all four features are continuous values (floating point numbers), which, naively, implies an infinitely large feature space.
Approach: Basic Q-Learning
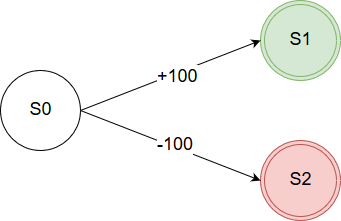
In the Machine Learning 1 course at my university, I got to know one of the most basic, yet widely-used reinforcement learning approaches, which is Q-Learning. The core of Q-Learning is to estimate a value for every possible pare of a state (s) and an action (a) by getting rewarded. Imagine the following graph, which consists of three states, while your agent is currently in s0. It can choose between two actions, one of which results in a good state s1 (e.g. having won the game), the other one results in a bad state s2 (e.g. having lost the game). Accordingly, the transition leading to the good (bad) state gives a reward of 100 (-100). If the agent performs action a0, the q-value of s0 will probably become negative (Q(s0, a0) < 0)), while Q(s0, a1) > 0.
The update of the q-value is done according to the following equation.

Basically, a (S, A)-tuple’s new q-value depends on its old q-value, the immediate reward received for the action and the maximum q-value achievable in the following state. So a (S, A)-pair’s q-value indirectly depends on all its successors’ q-values, which is expressed in the recursive function definition. By repeatedly walking through all nodes and transistions, the agent can update any (S, A)-pairs q-value, while the results of good and bad actions are slowly “backpropagated” from terminal nodes to early nodes. The agent ends up with a (usually multidimensional) table mapping states and actions to q-values, so that given any state, the best action can be picked by choosing the highest respective q-value.
My implementation
Since Q-Learning is pretty straightforward to understand and implement, I decided on picking that algorithm as a starting point for my CartPole challenge. I looked for other solutions, that also use CartPole and found this blog post by @tuzzer, which had partially inspired me during my implementation.
>> Code on GitHub (qcartpole.py)
Transforming the feature space
Actually the main challenge was to convert the continuous, 4-dimensional input space to a discrete space with a finite and preferably small, yet expressive, number of discrete states. The less states we have, the smaller the Q-table will be, the less steps the agent will need to properly learn its values. However, too few states might not hold enough information to properly represent the environment. The original domains of the input features are these.
- x (cart position) ∈ [-4.8, 4.8]
- x’ (cart velocity) ∈ [-3.4 * 10^38, 3.4 * 10^38]
- theta (angle) ∈ [-0.42, 0.42]
- theta’ (angle velocity) ∈ [-3.4 * 10^38, 3.4 * 10^38]
Finding the parameters
As can be seen, especially the velocities’ domains are extermely large. However, from @tuzzer‘s post I found that astonishingly small target intervals are sufficient. Therefore, I initially started by scaling theta down to a discrete interval theta ∈ [0, 6] ⊂ ℕ (which is, to be precise, just a set of integers {0..6}) and theta’ to theta' ∈ [0, 12] ⊂ ℕ . Inspired by @tuzzer‘s post, I dropped the x and x’ features completely, which corresponds to mapping any of their values to a single scalar. The motivation behind this is that the probability of the cart leaving the environment at the left or right border in only 200 time steps (after 200 steps, the environment automatically resets itself) is pretty slow and the resulting reduction in dimensionality more worthy.
The implementation of the actual Q-Learning algorithm is straightfoward and consits of a function to fetch the best action for a state from the q-table and another function to update the q-table based on the last action. Nothing special here.
More interesing are the algorithm’s hyperparameters, which include alpha (= learning rate), epsilon (= exploration rate) and gamma (= discount factor).
Alpha is used to “smooth” the updates and make them less radical, which, in the first place, prevents from errors caused by noise. Epsilon regulates between exploitation and exploration. Accordingly, instead of picking the best action in a state, with a chance of ε a random action is picked. This should prevent the algorithm from getting stuck in local minima. E.g. if a bad choice was made in the beginning, without ε the agent would continue on evaluating that suboptimal path and would never discover any other, potentially better, path. Gamma is used to penalize the agent if it takes long to reach its goal. However, in this case, gamma is set to constant 1 (no discount), since it’s even our goal to “survive” as long as possible.
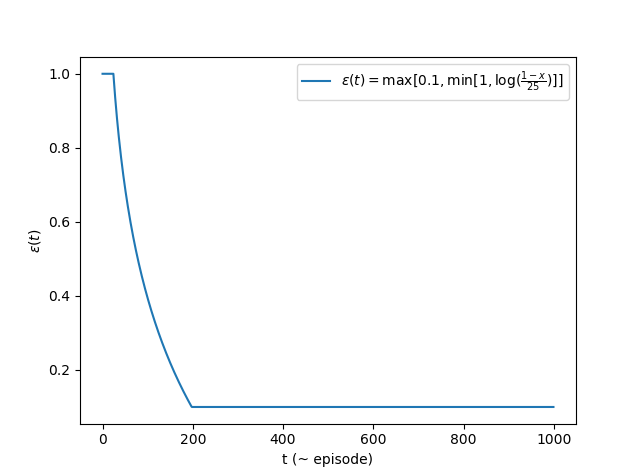
First I tried to choose the epsilon and alpha parameters as constants and experimented with various combinations. However, I always achieved only a very poor score (~ between 20 and 50 ticks). Then, again inspired by @tuzzer I decided to introduce an adaptive learning- and exploration rate, which starts with a high value and decreases by time (with each training episode). Astonishingly, this made a huge difference. Suddenly, my algorithm converged in about ~ 200 steps. Since I never thought that these hyperparameters made such an extreme difference (from not solving the challenge at all to doing pretty well), this was probably the most interesting finding from my CartPole project. I simply adpoted @tuzzer‘s adaptive function, which is visualized in the figure below (the minimum of 0.1 is a hyperparameter to be optimized).
Grid search
As my Q-Learning implementation with adaptive learning- and exploration rates was finished, I implemented an additional grid search to do some hyperparameter tuning. Goal was to find the optimal combination of feature interval lengths and lower bounds for alpha and epsilon. The following parameters turned out to perform best: 'buckets': (1, 1, 6, 12), 'min_alpha': 0.1, 'min_epsilon': 0.1. Additionally, I also could have evaluated different functions for calculating the adaptive rate, but I haven’t, yet.
>> Code on GitHub (qcartpole_gridsearch.py)
Result & Future Work
My final score was 188, as can be seen in the leaderboard. As I progress with my knowledge on machine learning, while practicing for the upcoming Machine Learning 2 exam, I want to continue improving my CartPole algorithm. Probably the next step will be to incorporate deep Q-Learning, which basically is Q-Learning with the only difference that the q-values are estimated by a deep neural net. The main (and probably only) advantage is the ability to handle way larger feature spaces. I’ll keep you guys up-to-date. I hope that I could encourage you to get started with Gym, or machine learning in general, too!