Since it took me a while to completely understand why a RAID 1+0 configuration should be better than a RAID 0+1 one in terms of failure tolerance I want to put my insights down.
First you should have a basic understanding of what the first two RAID levels are and what it means to nest them. Very basically at level 0 data gets striped, meaning a datum gets split up into two or more blocks that get stored on a different hard drive each. Goal is to improve read and write performance linearly to the number of disks used, because the fragments don’t have to be read sequentially anymore but in parallel. Level 1 is about mirroring a datum on two disks with the goal to improve security. Of course, both levels can be combined – you could either mirror striped data or stripe mirrored data which finally gives both: security and performance. In each case at least four disks are needed, while the half of the disks usually is a mirror. So if you took six disks you would do 3-striping. With eight disks you would do 4-striping and so on. Technically you could have more than one mirror (like doing 2-striping and having a 3-mirror or even more) but it’s very unusual.
The following diagrams shall illustrate these two ways and are useful for further explanations. In both cases we have a RAID with six disks.
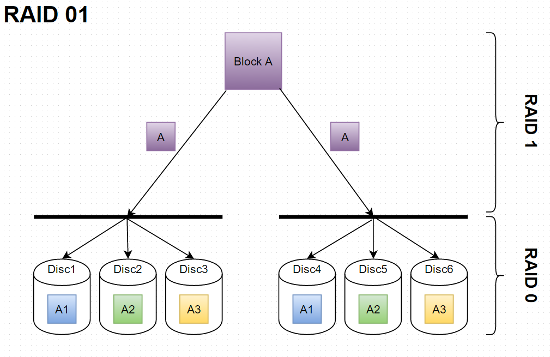
Disks 4, 5 and 6 are the mirrors of 1, 2 and 3.
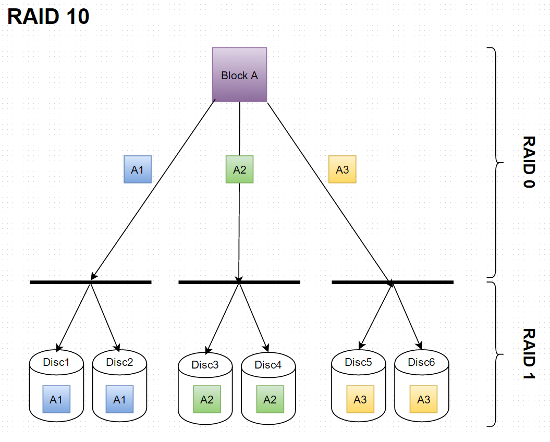
Disk 2 mirrors 1, 4 mirrors 3 and 6 mirrors 5.
We assert that RAID 10 is better in terms of fault tolerance because a total failure (= loss of data) is less likely. In other words if some drives crash in a RAID 01 configuration the chance that those are the right drives for suffering a data loss is higher.
First of all, both configurations can easily survive the crash of one drive. No matter which drive (see figures above) crashes, we have a second one with the exact same data on it in any case. Potentially both configurations can handle the simultaneous crash of two or even more drives (up to N/2), if they’re the right ones, but in the worst case, the second crash could end up in a total failure. What you need to make clear before understanding how RAID 01 is worse than RAID 10 is that a RAID 0 (sub)system immediately gets unusable if one of its disks goes down. This is apparent: In the upper figure (figure 1 from now on) data is divided up into three strips in both RAID 0 subsystem. So if one of their disks fails (assume a crash of Disc1), the subsystem is broken since the first two parts of a date won’t make sense without the third. You would still be in posession of all data, nothing is lost yet, but nevertheless the left RAID 0 subsystem is down. If a second drive fails this should only be 2 or 3 (since the left system in inacessible anyway) to keep the entire system up. Disc 4, 5 or 6 failing would cause a total crash. So the chance of the second failing disk resulting in a total crash is 3/5. Now take a look at figure 2. The crash of one disk in a RAID 1 (sub)system won’t make this subsystem go down because the RAID controller will seamlessly switch to the mirror drive which has exactly identical data. In figure 2 all RAID 0 disks (which actually are stanalone RAID 1 systems again) need to keep running for the entire system to stay up. So theoretically there wouldn’t be a problem with disks 1, 3 and 5 (or 2, 4 and 6) could crashing simultaneously. After one disk having failed (assume a crash of Disc1 again) the second one failing could be 3, 4, 5 or 6 – all but NOT 2. The probability of a total crash is 1/5 (namely Disc2 of the remaining five) now and therefore lower than 3/5 with RAID 01. Hope you got it…